ADR 0011: 汎用フェイルオーバー(活性駆動 seize、クロスプロバイダーアクションパリティ)
ステータス
提案済み。実験的実装として承認 — 2026-06-01。
ADR 0010: 捕捉所有権アービトレーション
(所有権マップ + ownershipEpoch)を消費し、
ADR 0008 の Phase C として延期されていた
フェイルオーバーを実現する。issue #74 に対応。実験的。
背景
CloudEdge は現在、協調的ドレイン(maintenance.drain)でのみ捕捉を移動する。
活性/ヘルス駆動のプロモーションはなく、プロバイダーごとのアクション
(secondary IP の assign/unassign、フォワーディング)は AWS のみで Azure/OCI/オンプレミスは
薄いか存在しない。#74 は、AWS / Azure / OCI / オンプレミス(VRRP/keepalived)を横断する
1 つのフェイルオーバーフレームワークを求めている。L3 の継続性(スタンバイのプロモーションにより
捕捉されたアドレスが引き続き提供される)を、統一されたスプリットブレイン/フラップ防御で
実現する。
ADR 0010 が所有権のプリミティブ(収束したオーナーマップ + ownershipEpoch フェンシング)を
提供する。この ADR は活性 → desired-owner → seize ループと
プロバイダー非依存のアクション層を追加する。
プロバイダーの reassignment セマンティクス(調査済み — seize の設計に反映)
- AWS:
assign-private-ip-addresses --allow-reassignmentが secondary IP を 別の ENI に移動する。非同期(インスタンスメタデータlocal-ipv4sで確認)、 last-writer-wins、関連 EIP も移動する。 - OCI:
assign-private-ip --unassign-if-already-assignedが同一サブネット内の 別 VNIC に強制的に reassign する。last-writer-wins。パブリック IP も移動する。 - Azure: 単一のアトミック reassign はない — 旧 NIC から ipConfig を削除 + 新 NIC に追加(2 操作。ETag/If-Match による楽観的同時実行制御が利用可能)。
したがって reassignment は普遍的にアトミックではない(AWS は非同期、Azure は 2 操作)。
フェイルオーバーは実験的であり、プロバイダーの assign セマンティクス + ownershipEpoch
フェンシング +(Phase 4)クラウドインベントリのドリフト reconciliation に依存する —
ロックには依存しない。
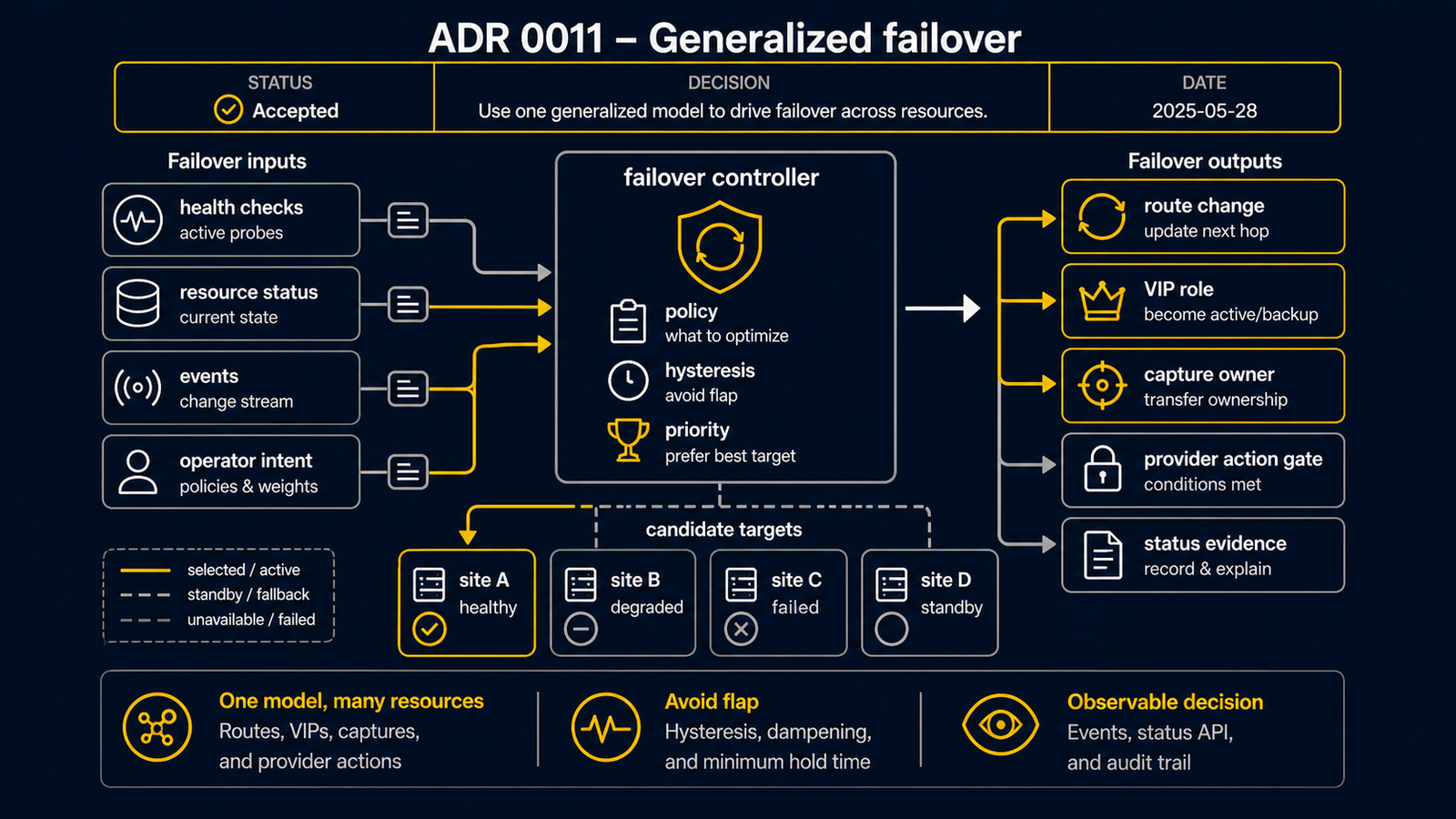
決定
統一された適格性と活性モデル
desired オーナー(ADR 0010 のアービトレーション)は適格なメンバーに対して計算される。 適格性は以下の交差:
maintenance.drain == false(ドレイン済み → 即座に除外);- ハートビートが新鮮 — 各メンバーが定期的に活性/ハートビートフェデレーションイベントを発行。 期限切れのハートビート(TTL)はプロモーションホールド後に不適格とする(後述);
HealthCheckが失敗していない(ポリシーに従う);- オンプレミス:VRRP マスター権限シグナル(
activeWhen{vrrp-master}、sam.EvaluateCaptureGate)— 非マスターは fail-closed。
活性はストリーム相対で評価される。各ノードの wall clock ではない:
「now」はプールのフェデレーションストリームで観測された最大イベント時刻
(streamMaxObservedAt)であり、メンバーは
lastHeartbeat(node) + heartbeatTTL + promotionHoldDuration <= streamMaxObservedAt
のとき stale となる。同じストリームを見た全ノードが同じ判定を計算するため、
適格セット — したがってオーナーマップ(ADR 0010)— は活性が追加されても
決定的に収束したままである。送信側のクロックスキューは
heartbeatTTL + promotionHoldDuration で吸収される。射影はローカルクロックに対して
未来のタイムスタンプをクランプしない(非決定的になるため) — 未来のスキューは
status/doctor 経由で可視化する。完全に停止したストリームはフェイルオーバーも停止するが、
これは正しい(「観測なしに障害を宣言しない」)。生存メンバーがいる接続コンポーネントは
ストリーム時刻を進め続ける。プロモーションホールドは一時的なギャップを吸収し
フラッピングを抑制する。maintenance.drain は即座の除外のまま
(協調的なのでホールド不要)。
Phase 2 の実装判断(2026-06-01 確定)
- ハートビートイベント: タイプ
routerd.mobility.member.heartbeat、group =MobilityPool.groupRef、payload{pool, node, emittedAt, seq}。 mobility コントローラーが reconcile tick で発行。autoFailover: trueの プールのみ、かつ自ノード(クラウドprovider-secondary-ipロール)のみ。heartbeatIntervalでレート制限。staleness 判定にはイベントのObservedAtを使用。lastHeartbeatはリースと同じ射影済みイベントストリームから導出される (wall-clock の混入なし)。 - ホールドフィールドは
ipOwnershipPolicyの下にフラットに配置:heartbeatInterval/heartbeatTTL/promotionHoldDuration(duration 文字列)。 リースのオーナー変更ホールドとは別。専用の状態テーブルなし — 適格性は純粋なlastHeartbeat + ttl + hold <= streamMaxObservedAtテスト。バリデーションはautoFailoverが true のときheartbeatInterval/heartbeatTTLを必須とし、heartbeatTTL >= heartbeatIntervalを要求。 - Seize アクション: 既存の
assign-secondary-ipverb にallowReassignmentパラメーターを追加する(新しい verb ではなく)。stale/dead な前オーナーが自身でunassignできないとき、新オーナーがアドレスを取得するために設定する。 AWS エグゼキューターはこれを--allow-reassignmentにマップする。ActionPlanの description/risk は seize/reassign として読める。ownershipEpochの スタンプ/フェンシングは ADR 0010 から変更なし。 autoFailoverゲート: ハートビートの staleness はautoFailover: trueのときのみアービトレーション適格性に入る。未設定/false のプールは現行動作を維持 (ドレインのみがオーナー変更を駆動)。#76 Phase 1 / SAM / captureEpoch パスには 影響なし。ハートビートはautoFailover: trueのプールでのみ発行/消費される。- スコープ: Phase 2 はクラウド
provider-secondary-ip+ AWS seize のみ。 オンプレミス(proxy-ARP / VRRP マスター)と Azure/OCI reassign エグゼキューターは Phase 3。 - 既知のフォローアップ: ハートビートイベントには TTL/expiry がないため、 停止したメンバーの最後のハートビートは staleness 判定のために観測可能なまま残る。 結果としてハートビート行は蓄積され prune されない (後の hygiene パスで追跡 — stale 判定が依存する最後のハートビートを prune してはならない)。
活性駆動 seize
適格オーナーが変わったとき(ドレイン、ハートビート期限切れ、ヘルス障害)、
ownershipEpoch がバンプし、新オーナーが seize する:secondary IP の
reassignment 付き acquire をプロバイダーに発行し、フォワーディングを有効にする。
旧オーナーのアクションは stale epoch を持ち、ゲートでフェンスされる。
autoFailover(ADR 0010 ipOwnershipPolicy)がこれを自動にするかをゲートする。
プロバイダー非依存のアクション層
- プランナーがプロバイダー非依存の所有権/アクション意図を発行する(desired な
(owner, address, verb)セット +ownershipEpoch)。エグゼキューターがプロバイダーの 差分を保持する(AWS--allow-reassignment、OCI--unassign-if-already-assigned、Azure remove+add)。これは既に AWS で使われている 共通のActionPlan+ エグゼキューター契約を汎用化したもの。 - オンプレミスはクラウドプロバイダーではない:その「アクション」はローカルデータプレーン (proxy-ARP/GARP/VIP)であり、プロバイダー API 呼び出しとしてではなく、 オンプレミスエグゼキューター / SAM-GARP ブリッジとして扱う。
フェーズ分割(この ADR)
- Phase 2: クラウド活性フェイルオーバー — ハートビートイベント + TTL +
プロモーションホールド + 統一適格性、
ownershipEpochバンプ、 クラウド secondary-IP seize(AWS 先行、実証済みパス)、autoFailoverゲート。 L3 が途切れないこと(プロモーション後にスタンバイがアドレスを提供する)の 強制障害 CI/lab テスト。 - Phase 3: プロバイダーアクションパリティ — Azure(remove+add ipConfig)と
OCI(
--unassign-if-already-assigned)エグゼキューター。オンプレミスエグゼキューター / SAM ブリッジによる VRRP/GARP 統合で、VRRP/keepalived フェイルオーバーを同じポリシーでカバー。 - Phase 4: クラウドインベントリ observe capability(
describe-secondary-ips)→ ドリフト/孤立/競合検出を status +doctorで可視化し、 実験的 seize を reconcile 済み所有権に硬化。所有権マップの管理 API。
結論
- 1 つのフェイルオーバーフレームワークがプロバイダーを横断する:活性/ヘルス/メンテナンス/VRRP が 統一された適格性モデルに入力される。プランナーはプロバイダー非依存。 プロバイダーごとの現実はエグゼキューターに閉じ込める。
- L3 の継続性はスタンバイのプロモーション + 捕捉済み IP の seize で達成され、
ownershipEpochでフェンスされる。正直な限界(コンセンサスなし、 プロバイダー reassignment は普遍的にアトミックではない)はドキュメントされ、 クラウドインベントリ(Phase 4)がドリフトギャップを埋める。 - オンプレミスはクラウドプロバイダーの型に押し込まれることなく統合される。