ADR 0011: 通用故障切換(活性驅動 seize、跨 provider action 對等)
狀態
已提議。核准為實驗性實作 — 2026-06-01。
消費 ADR 0010: Capture 所有權仲裁
(所有權對映 + ownershipEpoch),實現
ADR 0008 Phase C 中延期的
故障切換。對應 issue #74。實驗性。
背景
CloudEdge 目前僅透過協調式排空(maintenance.drain)移動 capture。
沒有活性/健康驅動的提升,各 provider 的 action
(secondary IP 的 assign/unassign、轉送)僅 AWS 完整,Azure/OCI/on-prem 薄弱或缺失。
#74 要求一個跨 AWS / Azure / OCI / on-prem(VRRP/keepalived)的
統一故障切換框架。以統一的腦裂/震盪防禦實現 L3 連續性
(standby 提升後 capture 的位址繼續提供服務)。
ADR 0010 提供所有權原語(收斂的 owner 對映 + ownershipEpoch fencing)。
此 ADR 新增活性 → desired-owner → seize 迴圈和
provider 無關的 action 層。
Provider 的 reassignment 語意(已調研 — 反映在 seize 設計中)
- AWS:
assign-private-ip-addresses --allow-reassignment將 secondary IP 移動到另一個 ENI。非同步(透過執行個體中繼資料local-ipv4s確認), last-writer-wins,關聯的 EIP 也會移動。 - OCI:
assign-private-ip --unassign-if-already-assigned在同一子網路內 強制 reassign 到另一個 VNIC。last-writer-wins。公用 IP 也會移動。 - Azure: 沒有單一原子 reassign — 從舊 NIC 刪除 ipConfig + 在新 NIC 新增(2 步操作。可使用 ETag/If-Match 的樂觀並行控制)。
因此 reassignment 並非普遍原子的(AWS 非同步、Azure 2 步)。
故障切換是實驗性的,依賴 provider 的 assign 語意 + ownershipEpoch
fencing +(Phase 4)雲端清單的漂移 reconciliation —
不依賴鎖。
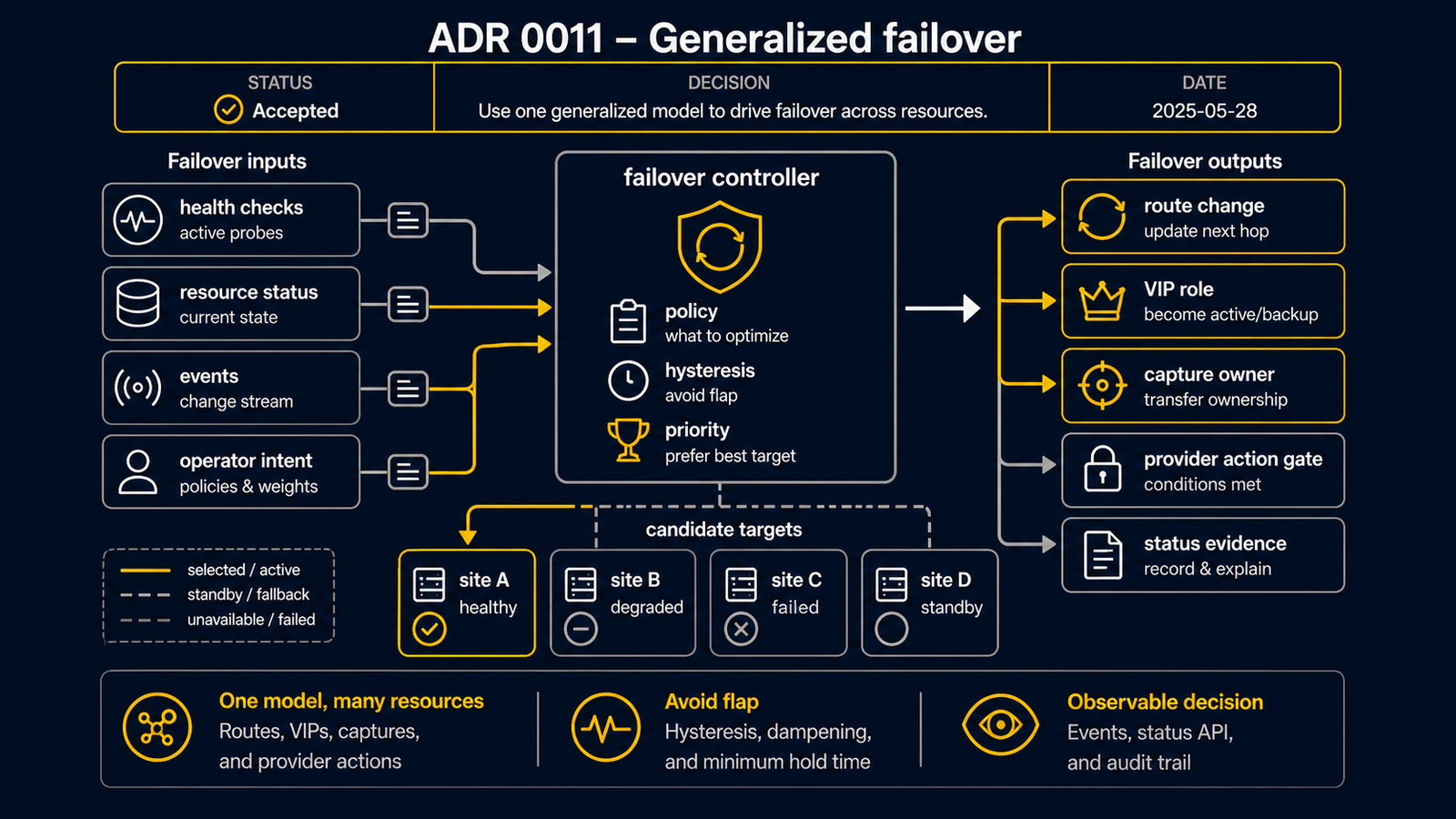
決策
統一的合格性與活性模型
desired owner(ADR 0010 的仲裁)對合格的成員計算。 合格性是以下條件的交集:
maintenance.drain == false(已排空 → 立即排除);- 心跳新鮮 — 每個成員定期發出活性/心跳 federation 事件。 過期的心跳(TTL)在提升保持期後標為不合格(見下文);
HealthCheck未失敗(按策略);- On-prem:VRRP master 權限訊號(
activeWhen{vrrp-master}、sam.EvaluateCaptureGate)— 非 master fail-closed。
活性以流相對方式評估。不使用每個節點的 wall clock:
「now」是在 pool 的 federation 流中觀測到的最大事件時間
(streamMaxObservedAt),當
lastHeartbeat(node) + heartbeatTTL + promotionHoldDuration <= streamMaxObservedAt
時成員為 stale。看到同一流的所有節點計算相同的判定,因此
合格集 — 從而 owner 對映(ADR 0010)— 在加入活性後仍
確定性收斂。傳送端的時鐘偏斜被
heartbeatTTL + promotionHoldDuration 吸收。投影不會
對本機時鐘鉗制未來的時間戳(會變成非確定性)— 未來偏斜透過
status/doctor 可視化。完全停止的流也會停止故障切換,但
這是正確的(「無觀測則不宣告故障」)。存活成員所在的連通分量
持續推進流時間。提升保持期吸收臨時間隙,
抑制震盪。maintenance.drain 保持立即排除
(協調式,無需保持期)。
Phase 2 的實作決策(2026-06-01 確定)
- 心跳事件: 類型
routerd.mobility.member.heartbeat,group =MobilityPool.groupRef,payload{pool, node, emittedAt, seq}。 mobility 控制器在 reconcile tick 發出。僅對autoFailover: true的 pool,且僅自節點(雲端provider-secondary-ip角色)。 以heartbeatInterval做速率限制。staleness 判定使用事件的ObservedAt。lastHeartbeat從與 lease 相同的投影事件流導出 (無 wall-clock 混入)。 - 保持期欄位平鋪在
ipOwnershipPolicy下:heartbeatInterval/heartbeatTTL/promotionHoldDuration(duration 字串)。 與 lease 的 owner 變更保持期分開。無專用狀態資料表 — 合格性是純粹的lastHeartbeat + ttl + hold <= streamMaxObservedAt測試。驗證在autoFailover為 true 時要求heartbeatInterval/heartbeatTTL必填, 並要求heartbeatTTL >= heartbeatInterval。 - Seize action: 在現有
assign-secondary-ipverb 上增加allowReassignment參數(而非新 verb)。當 stale/dead 的前 owner 無法自行unassign時, 新 owner 設定此參數來取得位址。 AWS executor 將其對映為--allow-reassignment。ActionPlan的 description/risk 可讀為 seize/reassign。ownershipEpoch的 打戳/fencing 與 ADR 0010 相同。 autoFailover閘門: 心跳 staleness 僅當autoFailover: true時才進入仲裁合格性。未設定/false 的 pool 保持現行行為 (僅排空驅動 owner 變更)。對 #76 Phase 1 / SAM / captureEpoch 路徑 無影響。心跳僅在autoFailover: true的 pool 中發出/消費。- 範圍: Phase 2 僅涵蓋雲端
provider-secondary-ip+ AWS seize。 On-prem(proxy-ARP / VRRP master)和 Azure/OCI reassign executor 在 Phase 3。 - 已知後續: 心跳事件沒有 TTL/expiry,因此 停止成員的最後一個心跳為 staleness 判定保持可觀測。 結果是心跳列會累積不被清理 (後續 hygiene pass 追蹤 — 不得清理 stale 判定依賴的最後心跳)。
活性驅動 seize
當合格 owner 變更時(排空、心跳過期、健康故障),
ownershipEpoch 遞增,新 owner seize:向 provider 發出帶
reassignment 的 secondary IP acquire,啟用轉送。
舊 owner 的 action 持有 stale epoch,在閘門處被圍欄。
autoFailover(ADR 0010 ipOwnershipPolicy)閘門控制是否自動化。
Provider 無關的 action 層
- planner 發出 provider 無關的所有權/action 意圖(desired 的
(owner, address, verb)集 +ownershipEpoch)。executor 持有 provider 差異(AWS--allow-reassignment、OCI--unassign-if-already-assigned、Azure remove+add)。這是將已用於 AWS 的 通用ActionPlan+ executor 契約泛化。 - On-prem 不是雲 provider:其「action」是本機資料平面 (proxy-ARP/GARP/VIP),作為 on-prem executor / SAM-GARP 橋接處理, 而非 provider API 呼叫。
階段劃分(此 ADR)
- Phase 2: 雲端活性故障切換 — 心跳事件 + TTL +
提升保持期 + 統一合格性、
ownershipEpoch遞增、 雲端 secondary-IP seize(AWS 先行,已驗證路徑)、autoFailover閘門。 L3 不中斷(提升後 standby 提供位址)的 強制故障 CI/lab 測試。 - Phase 3: Provider action 對等 — Azure(remove+add ipConfig)和
OCI(
--unassign-if-already-assigned)executor。On-prem executor / SAM 橋接的 VRRP/GARP 整合,以同一策略涵蓋 VRRP/keepalived 故障切換。 - Phase 4: 雲端清單 observe capability(
describe-secondary-ips)→ 漂移/孤立/衝突偵測在 status +doctor可視化, 將實驗性 seize 強化為 reconcile 過的所有權。所有權對映的管理 API。
結論
- 一個故障切換框架跨越 provider:活性/健康/維護/VRRP 作為 統一合格性模型的輸入。planner 與 provider 無關。 每個 provider 的現實封裝在 executor 中。
- L3 連續性透過 standby 提升 + capture IP 的 seize 實現,
由
ownershipEpoch圍欄。誠實的限制(無共識、 provider reassignment 並非普遍原子)被記錄, 雲端清單(Phase 4)填補漂移缺口。 - On-prem 被整合而不被強塞入雲 provider 的模型中。