ADR 0008: フェンシングトークンによる捕捉協調(epoch フェンス付きレベル射影)
ステータス
提案済み。実験的実装として承認 — 2026-05-31。
この ADR は ADR 0006: CloudEdge Event Federation、 ADR 0007: Provider Action Execution、および Selective Address Mobility データプレーンを土台とする。 実験的である。
「永続的 de-provision マーカー」修正(コミット 26f2a729、issue #70)で導入された de-provision メカニズムを置き換える。その修正は unassign を永続的にしたが、 命令的な cancel パス(アドレスが再び desired になったとき、進行中の de-provision を キャンセルする)を残していた。その cancel パスは非決定的 — reconcile のタイミングと 実行の競合が起きる — であり、状態の合流点をパッチしてもフラキーを除去できなかった。 この ADR はそれを epoch フェンス付きレベル射影に置き換える。
背景
Selective Address Mobility のモバイル /32 は、任意の時点で正確に 1 つの捕捉ホルダーを持つ、一意性制約付き共有リソースである(any-origin 対称アービトレーションの単一所有者不変条件)。アドレスを「保持する」とは、物理的な捕捉を所有すること:クラウド NIC 上のプロバイダー secondary IP 割り当て(AWS ENI / Azure NIC / OCI VNIC)、またはオンプレミスの proxy-ARP + GARP。
捕捉はホルダー間で 2 つの方法で移動する:
- 協調的 / 計画的 — メンテナンスドレイン。アクティブホルダーが協力する。
- 突発的 / 障害 — ホルダーのホストが停止またはパーティションされる。協力できないため、 スタンバイが捕捉を seize(奪取)する必要がある。
de-provision(secondary IP の unassign / フォワーディングの無効化)は捕捉の解放、
assign は取得である。このバグはフラキーテストとして顕在化した
(TestServeChainMobilityCancelsPendingDeprovisionWhenDesiredAgain、-race なしで約 3/30 失敗):
再捕捉時に進行中の de-provision がキャンセルされないことがあり、
孤立したマーカー / pending アクションが残った。cancel の join 先をパッチしてもフラキーは除去できなかった。
進行中の作業の命令的キャンセルは、レベルトリガーの reconciler にとって間違った抽象化だからである。
参照した理論(分散協調)
- フェンシングトークン(Kleppmann, How to do distributed locking):TTL 付きリース/ロックは 活性に必要(停止したホルダーのリースが期限切れになり、スタンバイが引き継げる)だが、 安全性には不十分 — 一時停止/遅延/復活した(「ゾンビ」)旧ホルダーが、リース期限切れ後も 操作できてしまう。「書き込み直前に期限を確認しても修正できない。」唯一の修正策は、 保護されたリソースがチェックする単調増加フェンシングトークンで、 見たことのある最大値より低いトークンを持つ操作を拒否すること。
- Generation / term / epoch:Raft の term、ZooKeeper の epoch / zxid 等は同じ 単調増加フェンシングトークンで、ゾンビのフェンシングと乖離した状態の reconcile に使われる。 「下流システムは stale epoch を持つ操作を拒否しなければならない。」
- レベルトリガー reconciliation(Kubernetes コントローラー):毎 tick、観測状態から desired 状態に reconcile する。冪等。エッジでは動作しない。 レベルループに接ぎ木されたエッジロジック(「re-desire 時に X をキャンセル」)は競合する。
- スプリットブレイン / HA フェイルオーバー(Pacemaker STONITH、keepalived VRRP + EC2
AssignPrivateIpAddresses):フローティング IP は正確に 1 つのマスターが保持 (IPaddr2 + GARP)。STONITH は引き継ぎ前に旧ノードの停止を保証する。 ハートビート間隔は検出レイテンシとスプリットブレインリスクのトレードオフ — ただし 安全性は提供しない。安全性はフェンシング/クォーラムによる。
routerd 固有の制約
ここでの「保護されたリソース」はクラウドプロバイダー API とオンプレミスの ARP テーブルであり、 いずれもフェンシングトークンをネイティブにチェックしない — AWS は「epoch 33 付きの unassign」を epoch 34 が既に起きたからといって拒否しない。フェンシングを実リソースまで 押し込むことはできない。 routerd は自身が制御する最後のゲートでフェンスを強制する必要がある: アクションインポート / エグゼキューター境界(「フェンシングプロキシ」パターン)。
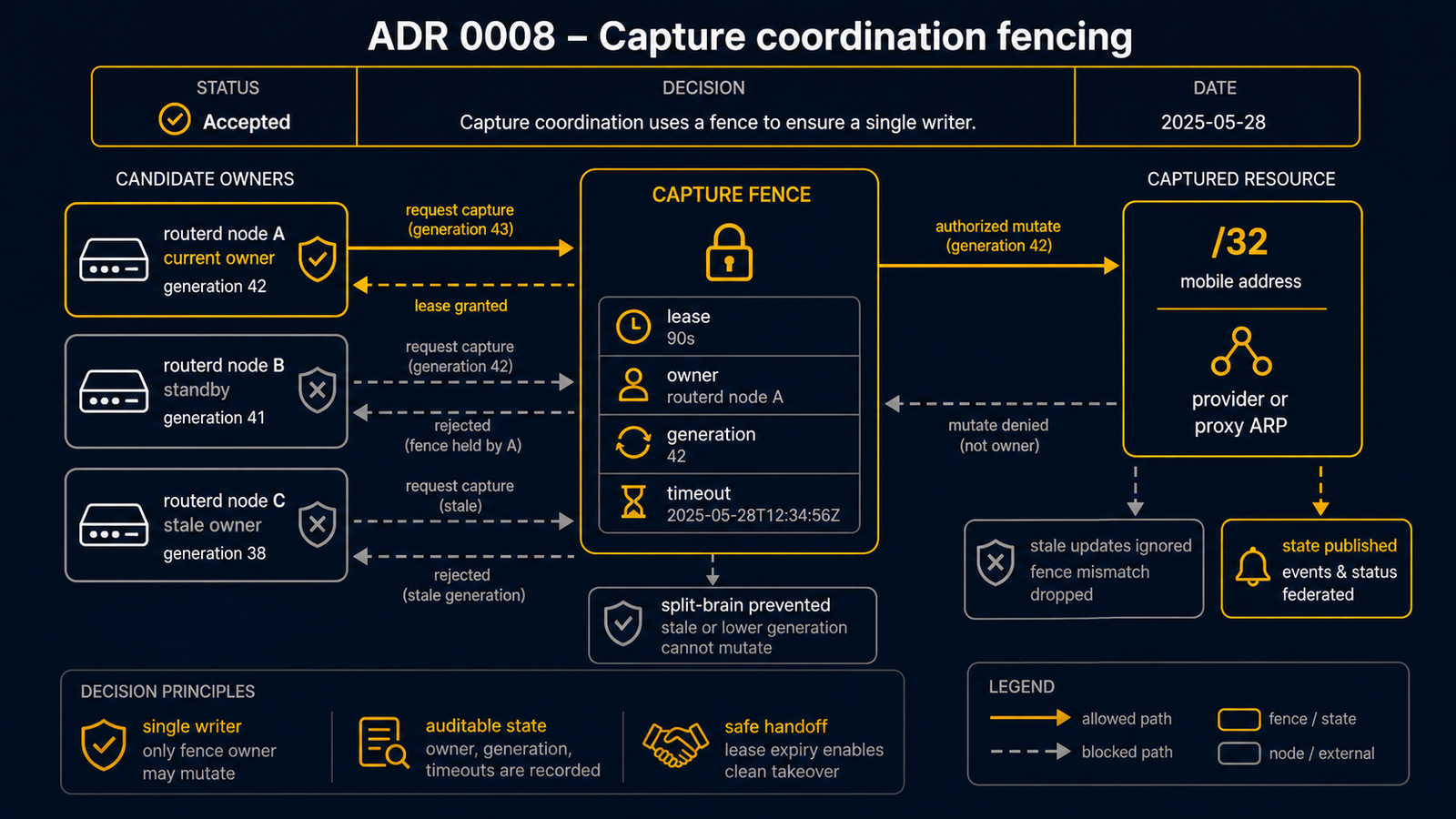
決定
1. captureEpoch — (pool, address, captureDomain) ごとの単調増加フェンシングトークン
永続化された厳密に単調増加するローカルカウンター。
(pool, address, captureDomain) をキーとし、desired 捕捉ホルダーが変わるたびにインクリメントされる
— 以前のホルダーへの再捕捉を含む。AddressLease の epoch とは別のもの:
AddressLeaseepoch = ロケーションオーナー(アドレスを所有する者)の epoch。captureEpoch= 物理捕捉ホルダー(secondary IP を attach する / proxy-ARP に応答する者)の epoch。
これらは異なるライフサイクルであり、混同してはならない。wall-clock time(now)は
トークンとして使ってはならない — ノード間で非単調であり churn を起こす。
これが置き換え前の修正の潜在的欠陥だった。captureDomain はプレースメントグループの
スコープ(provider:<ref>:placement:<group>)で、同一プロバイダーグループ内で
同じアドレスを争う全 routerd が 1 つの epoch ラインを共有する。
2. すべてのプロバイダーアクションに (captureEpoch, captureKey, holder) をスタンプ
プランナーが assign-secondary-ip、unassign-secondary-ip、フォワーディングアクションに
captureEpoch、captureKey、アクションの対象ホルダー(acquire → desired ホルダー、
release → 退去ノード)をスタンプする。idempotencyKey は :epoch:<N> でサフィックスされるため、
捕捉 epoch N のアクションは epoch N+1 とは別の安定したキーになる — かつ
同一 epoch 内の reconcile 間では安定する(churn なし)。
3. de-provision の意図はレベル射影であり、ワークキューではない
de-provision の作業セット = 現在の captureEpoch で評価された
(以前捕捉済み − 現在 desired) の射影であり、毎回の reconcile で再計算される。
再捕捉は何も「キャンセル」しない:アドレスが desired 状態に再び入るため射影から落ち、
captureEpoch がバンプする。命令的な cancel パスは存在しない。
永続マーカーテーブルは outbox として保持する(DynamicConfigPart だけでは
インポート前に意図が失われる — 元の #70 障害)。ただしマーカーは
epoch キー付きの射影アイテムであり、キャンセル可能なエッジ状態ではない。
stale マーカーは同じフェンス(dropStaleDeprovisionMarkers)で除去される。
4. インポート / エグゼキューターゲートでフェンス
アドレス X のプロバイダーアクションをインポートする前、およびジャーナルをスイープするとき、
その captureEpoch/ホルダーを X の現在の captureEpoch と比較する:
- epoch が現在と不一致、または ホルダーがもはや現在のものでない acquire、
または ホルダーがまだ現在のものである release → アクションは stale → スキップ(フェンス)、
既にインポート済みの pending/approved な stale アクションは
skippedにマークされる。 置き換え済みマーカーを復活させようとする旧 reconcile の復活は、古い epoch を持っているため このゲートで死ぬ。
この単一の決定的ゲートが、散在していた
cancelMarkerPlansForDesired / CancelActionByIdempotencyKey のキャンセルロジックを置き換える。
5. 安全である理由 — と正直な限界
- ノード内: ローカル
captureEpochゲートはノードの reconcile ループ内で単調かつ直列である。 stale なローカル reconcile を決定的にフェンスする。これが #70 のフラキーを除去するもの。 - ノード間(以前の過大な主張の訂正 — ノードごとの DB ゲートはクロスノードでは
linearizable ではない):安全性は構造的であり、
(a) プロバイダーの単一割り当てセマンティクス — secondary IP は正確に 1 つの NIC 上に存在 —
と (b) reassignment 付き acquire(AWS
assign-private-ip --allow-reassignmentが IP を アトミックに移動し、停止したホルダーの release を待たない — release-before-acquire では ホスト障害時に活性が失われる)と (c) NIC スコープの stale 操作(旧ホルダーのunassignは自身の NIC のみを対象とするため、 新ホルダーの NIC を剥がすことはできない)の組み合わせ。 - オンプレミスの proxy-ARP はより弱い。クラウドと同等に見せかけてはならない: アトミックな reassignment はない。ここでの安全性は 捕捉権限としての VRRP/keepalived マスター状態 — 非アクティブノードは fail-closed (proxy-ARP なし、route lowering なし)、マスターのみが proxy-ARP + GARP を発行する — に依拠する。 パーティション下での完全な安全性は STONITH / クォーラムなしでは達成不可能であり、 スコープ外。
- 活性と安全性のバジェット: リース TTL / ハートビート間隔は検出レイテンシを調整する
(短すぎる → フラップ、長すぎる → 回復遅延)。keepalived の
advert_intと 既存のdeprovisionHoldDurationヒステリシスに対応する。安全性はこのつまみに依存してはならない — 安全性を提供するのは単調増加captureEpochのみ。Kleppmann の教訓の具体化。
フェーズ分割
- Phase A(この ADR の最小スコープ — #70 を決定的に修正):
captureEpochの導入。 アクションへのスタンプ。マーカーを epoch キー付きレベル射影にする。 stale epoch / ホルダー不一致でのインポート時フェンス。cancel パスと wall-clock ライフサイクルキーの除去。受け入れ条件:TestServeChainMobilityCancelsPendingDeprovisionWhenDesiredAgainが-count=100(および-race)で決定的に通過、アサーション緩和(< 2)は 正確な決定的カウントに置き換え、re-emit テストは green を維持、 テストを緩和して通過させることはしない。 - Phase B(後日): 突発的 seize のための execute-time ゲート(import-time に加えて)。
- Phase C(後日 — フェイルオーバー機能): 活性駆動プレースメント —
maintenance.drainフラグだけでなく、リース TTL / ハートビートによって アクティベーションを駆動する。突発的なホスト障害がスタンバイの seize(reassignment 付き acquire)をトリガーし、ゾンビ復活に対してフェンスされる。 これは D4(オンプレミス VRRP フェイルオーバー)のクラウド版であり、 ドレインのみの migration(D5)を AWS / Azure / OCI 上の透過的なホストメンテナンス・ 物理ホスト障害フェイルオーバーに変える。
結論
- フラキーな de-provision/再捕捉レースは、上書きではなく抽象化レベルで除去された: 1 つの決定的な epoch フェンス付き計算が、散在する命令的キャンセルを置き換える。
- routerd は、同じゲートが後に突発的フェイルオーバーの seize にも使える原則的な
フェンシングトークン(
captureEpoch)を獲得する — #70 修正とフェイルオーバー機能は 1 つの機構を共有する。 - 設計は、クラウド捕捉は強く安全(プロバイダーの単一割り当て + reassignment + NIC スコープ + epoch)であり、オンプレミスの proxy-ARP はベストエフォート (VRRP マスター権限 + fail-closed + GARP)であることを、等価と暗示するのではなく 明示している。
- simplicity-first の範囲にとどまる:コンセンサスプロトコル(Paxos/Raft)は導入しない。 アドレスごとの単調増加カウンター + 単一フェンスゲートが協調面のすべて。
-race受け入れ基準の修正は、既存のイベントバスデータレース(publish が unsubscribe の チャネル close と競合)も発見・修正した。companion のfix(bus)コミットを参照。