routerd は現在 FRR ではなく GoBGP ベースの routerd-bgp デーモンを使うため、本ページの一部は旧構成に基づく記述です。最新の推奨構成は「リリースと安定版」の 安定版マイルストーン を参照してください。
BGP / FRR 制御プレーン統合設計
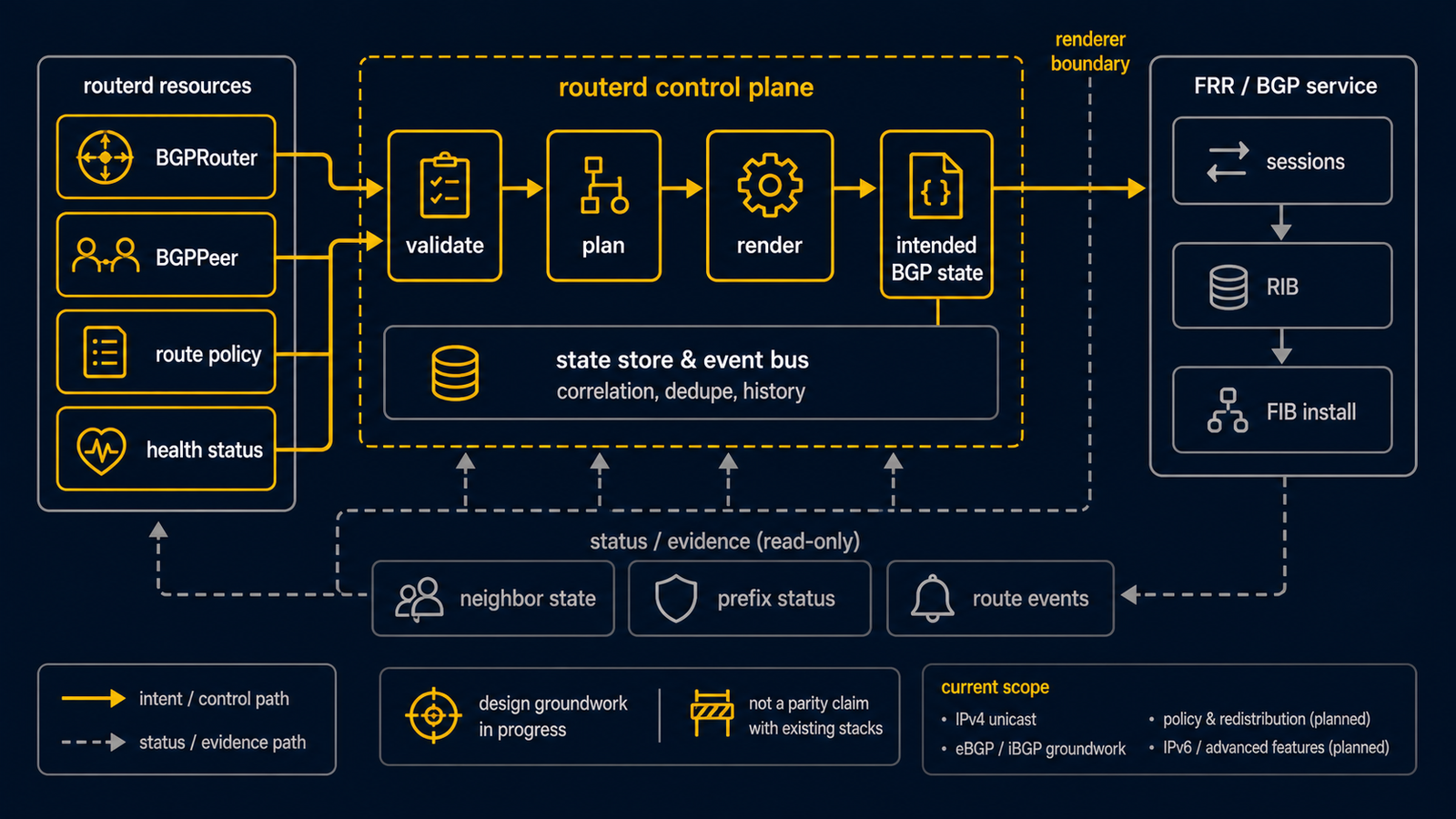
この文書では、routerd が BGP と関連ルーティングプロトコルのために FRR の制御プレーン(vtysh、frr-reload.py、デーモンソケット)とやり取りする設計をまとめます。
課題の整理
TCP VTY のリッスンを無効化する FRR ビルドでは(vty_serv_start() 内で port=0)、tcp/2605(bgpd の VTY リッスン)を前提とする routerd の従来の準備完了判定が常に偽になります。その結果、コントローラーは生成済み設定に対して frr-reload.py を実行する代わりに FRR を繰り返し再起動し、FRR は BGP インスタンスが未設定のまま残ります(router bgp X のスタンザがなく、tcp/179 もリッスンしない状態)。
手動で frr-reload.py --reload /run/routerd/frr/routerd.conf を実行すると状態が復旧します。これは、生成済み設定が正しいこと、そして frr-reload.py がインスタンス無しの状態から BGP インスタンスを作成できることを示しています。
OSS で確認した事実(ソースレベル)
- FRR
lib/vty.cのvty_serv_start(addr, port, path): TCP リッスンはport != 0のときだけ有効になります。Unix の<daemon>.vtyソケットはこれとは独立です(#ifdef VTYSH)。TCP VTY を無効化したビルドでも、Unix ソケットは/run/frr/<daemon>.vtyまたは/var/run/frr/<daemon>.vtyに存在します。 - FRR
tools/frr-reload.pyのis_config_available(): 準備完了は、vtysh -c "configure"が成功し、かつ「configuration is locked」を報告しないことで判定します。TCP VTY のリッスンは参照しません。 frr-reload.pyは「新しい BGP インスタンス」を新規コンテキスト(lines_to_add)として扱うため、インスタンス無しの状態からの初回収束もこのスクリプトの対象範囲です。--stdoutはログのリダイレクトのみで、リロードの動作は変えません。
設計
準備完了プローブ
コントローラーは、1 回の vtysh -c "show running-config" のやり取りで FRR 制御プレーンをプローブします。
- 終了コード 0 → FRR 制御プレーンに到達できます。この出力は準備完了の信号としても、
runningConfigMatchesへの入力としても使います。1 回のやり取りで 2 つの目的を兼ねます。 - 終了コードが 0 以外で
failed to connect to any daemons→ 制御に到達できません。同じ調整の中で、その経路ごとのタイムアウトが切れるまで再試行し、切れたらFRRControlUnavailableを表に出して、定期調整に次の試行を任せます。 - 終了コードが 0 以外で別のエラー → stderr を status に記録し、再試行のうえでは制御に到達できないものとして扱います。
TCP ベースの判定は廃止します。/run/frr/<daemon>.vty(および /var/run/frr/<daemon>.vty)の Unix ソケットファイルの有無は status に診断情報として記録しますが、判定の根拠には決して使いません。デーモンの初期化中や再起動の競合中は、ファイルが存在しても vtysh のやり取りが失敗することがあるためです。
調整フロー
FRR のサービス状態は、すべての調整の前提条件です。コントローラーは「FRR が動いている」状態を、一度きりのセットアップ手順ではなく、毎サイクル確認して回復させるべきものとして扱います。これは v2007 のホットフィックスで得た教訓です。あのときは、誤った TCP VTY 判定を取り除いた際に、初回起動時に FRR を最初に起動する経路までいっしょに取り除いてしまいました。
1. /run/routerd/frr/routerd.conf と /etc/frr/daemons を生成します。
2. プラットフォームのサービスマネージャー経由で FRR のサービス状態を確認します
(`systemctl is-active frr`)。
- active/running → 再起動せずに続行します。
- inactive/stopped → FRR を有効化して起動します。
- failed → FRR を再起動します。
- unknown → ログを残し、failed として扱います。
これは /etc/frr/daemons の変更有無に関わらず、毎調整で実行します。
3. /etc/frr/daemons が変わった場合:
FRR を有効化して再起動します (上記の状態起点の処理に加えて実行)。
waitFRRControlReady(ctx, 30s) を実行します。
4. それ以外の場合:
waitFRRControlReady(ctx, 5s) を実行します。
4. 準備完了がタイムアウトした場合:
status = FRRControlUnavailable (調整内の再試行予算がまだ残っていれば
FRRStarting)。Pending を返します。定期調整 (既定 15s) が自然に再試行します。
5. vtysh -C -f /run/routerd/frr/routerd.conf (構文検証)。
0 以外なら:
status = FRRSyntaxInvalid (設定を直すまで終端状態)。
6. frr-reload.py --reload --stdout /run/routerd/frr/routerd.conf。
一時的な "configuration is locked" 出力には、既存の
transient-lock バックオフ (500ms) で再試行します。
それ以外の 0 以外の終了なら:
status = FRRReloadFailed。stderr を保存します。Pending を返し、
次の調整で再試行します。
7. 同じ vtysh -c "show running-config" で runningConfigMatches を確認します。
- 終了コード 0 で、生成した `router bgp <asn>` スタンザを含む → Healthy。
- 終了コード 0 だが、スタンザが無い → 不一致 → 再びリロード
(連続して N 回検証に失敗したら FRRReloadIncomplete に格上げして再試行)。
- 終了コード 0 以外 (failed to connect) → FRRControlUnavailable。
waitFRRControlReady は再利用できるヘルパーで、デーモン再起動の経路(長めのタイムアウト)と、リロードのみの経路(短めのタイムアウト)の両方で使います。内部では、成功するかタイムアウトするまで vtysh -c "show running-config" をポーリングし、毎回 Unix ソケットファイルの有無を診断情報としてログに残します。
ステータスのフィールド
BGPRouter / BGPPeer の status オブジェクトは次を公開します。
LastControlProbeAt,LastControlProbeError: 直近の vtysh のやり取りの結果。LastReloadAttemptAt,LastReloadStderr: 直近の frr-reload.py の実行内容(transient-lock の再試行を含む)。LastReloadDurationMs,TransientLockRetries: 運用上のメトリクス。Phaseenum は次を追加して拡張します。HealthyPendingError
- 理由・状態コード:
FRRStarting(一時的。調整内の再試行予算の範囲内)FRRControlUnavailable(タイムアウト超過。定期調整が再試行)FRRSyntaxInvalid(終端状態。生成済み設定をユーザーが直す必要あり)FRRReloadFailed(次の調整で再試行)FRRReloadIncomplete(リロードは成功を返したが runningConfig に 生成したスタンザがまだ無い。次の調整で再試行)Healthy
タイムアウト・再試行予算
| 経路 | タイムアウト | ポーリング | 定期調整 |
|---|---|---|---|
| デーモン再起動 → 準備完了 | 30 s | 1 s | 15 s を継承 |
| リロードのみ → 準備完了 | 5 s | 500 ms | 15 s を継承 |
| configure-locked の一時的な再試行 | 1 回あたり 500 ms | 最大 3 回 | — |
指数バックオフも、絶対的な失敗しきい値もありません。定期調整が自然に永遠に再試行します。介入はオペレーターの判断に委ね、上記の明示的な理由コードで状況を表に出します。
routerd serve の重複防止ガード
scripts/build-live-iso.sh と live-autostart.sh は、すでに /run/routerd/routerd.sock を所有する routerd serve がある場合、2 つ目を起動してはいけません。このガードは自動起動を冪等に保ちます。ただし、起動時の最初の自動起動パスは、設定の引き継ぎ境界でもあります。永続化されたサービスが USB の設定復元より先に routerd serve を起動した場合、live-autostart.sh は既存プロセスを成功として扱うのではなく、apply のあとでそのサービスを再起動しなければなりません。この再起動は reason=LiveISOStaleServeRestarted でログに残します。起動マーカーは /run/routerd 配下に置き、起動ごとにこの引き継ぎを評価し直します。重複防止ガードが無いと、2 つの routerd コントローラーが FRR のサービスロック(systemctl の flock)を奪い合い、フェーズ 0 の証跡で見られた ERROR: frr stopped by something else という症状を起こします。復元後の再起動が無いと、早期の serve プロセスが復元済み設定を取りこぼし、BGP を apply-once の Rendered 引き継ぎ状態のまま残してしまいます。
これは BGP 判定の変更と同じホットフィックスで、独立してリバートでき、変更履歴を明確にするため、別コミットとして提供します。
Healthy 判定(AND 条件)
BGPRouter は、次のすべてを確認できたときだけ Healthy になります。
- プラットフォームのサービスマネージャーで FRR のサービス状態が
active/runningである。 - 宣言したすべての FRR デーモン(
/etc/frr/daemons記載分)がFAILEDではなく稼働している。 vtysh -c "show running-config"が終了コード 0 を返す。- 設定したアドレスで
:179がリッスンしている(BGP デーモンが動作している)。 - 出力に、生成した
router bgp <our-asn>スタンザを含む。
いずれかの条件が満たされない場合、コントローラーは(status フィールド一覧に沿った)理由コードを表に出し、Pending または Error のままにします。FRR が落ちている間に status の経路が Healthy へ崩れてはいけません。v2007 のリグレッション(すべての FRR デーモンが FAILED なのに routerctl get status が Healthy を報告した)は、まさにこの AND 判定が防ぐ失敗モードです。
受け入れ基準
- ライブ ISO が起動すると、
routerd serveがちょうど 1 つだけ動き、手動のfrr-reload.pyなしでvtysh -c "show running-config"に BGProuter bgp Xが現れ、tcp/179がリッスンする。 - 起動時に FRR サービスが
FAILED状態で立ち上がっても、コントローラーが検出して回復する(手動のsystemctl start frrは不要)。 - FRR が落ちている間、または
:179がリッスンしていない間は、routerctl get statusがHealthyを報告しない。 - TCP VTY を有効にした Linux ディストリビューションでもリグレッションを起こさない。
runningConfigMatchesがfailed to connectを一致として扱わない。- 上記すべての status 理由コードが、対応する失敗モードで生成される。
テストシナリオ
- 初回起動(tcp/2605 なし): vtysh は成功、running-config は最小限 → リロードが実行され、BGP インスタンスが作成され、
tcp/179がリッスンする。 - Linux ディストリビューションの初回起動(tcp/2605 がリッスン): リロードが実行され、runningConfig の差分にも status にもリグレッションが無い。
- 壊れた状態からの回復: BGP インスタンスが無いまま FRR が動いているルーターに routerd バイナリをアップグレード → 手動介入なしでリロードが実行される。
- デーモン再起動中に vtysh が一時的に
failed to connect→ コントローラーは準備完了予算の範囲内で待ち、vtysh が回復したら検証とリロードへ進む。 - vtysh が恒久的に失敗 → タイムアウト後に
FRRControlUnavailable。定期調整が再試行する。 vtysh -C -fが構文を拒否 →FRRSyntaxInvalid。リロードもチャーンも無い。frr-reload.pyが 0 以外で終了 →FRRReloadFailed。次の調整で再試行する。frr-reload.pyは 0 で終了したが running-config に生成したスタンザがまだ無い →FRRReloadIncomplete。次の調整で再試行する。- configure-lock の一時的な発生 → 既存の transient-lock 再試行経路が成功裏に完了する。
- serve プロセスがソケットを保持している間に
live-autostart.shを再呼び出し → 2 つ目のプロセスを起動せず終了コード 0 で終了する。 - ライブ ISO のスモークテスト(リリースゲート): 新しい ISO を起動し、BGP が自律的に収束することを確認する。
- 起動時に FRR サービスが FAILED 状態で立ち上がる: routerd は
systemctl start frr(または再起動)を実行し、手動介入なしでデーモンを回復しなければならない。デーモンが稼働するまで status は FAILED 状態を反映する。 - status の正確さ: 一度 Healthy だった状態のあとに FRR を強制停止(
systemctl stop frr)すると、次の調整はHealthyではなくFRRControlUnavailableまたはFRRServiceDownを表に出さなければならない。失敗している間、BGPRouter status のlastSuccessTimeは進んではいけない。
FRR Issue #8403(graceful-restart の終了コード != 0)
FRR 8.4.x ごろより前のバージョンでは、bgp graceful-restart を含む設定で frr-reload.py が 0 以外で終了することがあります。ライブ ISO は新しい FRR リリースを同梱しますが、frr -v をフェーズ 0 の証跡として取得し、同梱バージョンが該当する場合だけ追加対応します。投機的なバージョン検出コードはホットフィックスには入れません。
アーキテクチャの追加対応(ホットフィックス後)
ホットフィックスが入ったあと、FRR のプローブ・リロードの責務を pkg/frr/ に切り出し、Prober インターフェースと、その Probe・Validate・Reload・RunningConfig メソッドがすべての vtysh / frr-reload.py の呼び出しをカプセル化する DefaultProber を用意します。これにより BGP コントローラーは Prober への薄いディスパッチになり、単体でモックテストができ、将来のコントローラー(OSPF、IS-IS など)からも再利用できます。
ホットフィックス自体は差分を最小化するため BGP コントローラーに置いたまま、後続リリースで pkg/frr/ へ移行する明確な計画を立てます。
参考資料
- FRR
lib/vty.cのvty_serv_start,vty_serv_un - FRR
tools/frr-reload.pyのis_config_available, context-diff - FRR ドキュメント:
docs.frrouting.org/en/latest/frr-reload.html - FRR Issue #8403 (graceful-restart の終了コード)
- VyOS
python/vyos/frr.py(参考: 事前プローブなしのリロード) - k8s-rt-02 のフェーズ 0 証跡(
/tmp/bgp-pre-reload/)