routerd 目前使用以 GoBGP 为基础的 routerd-bgp 守护进程,而非 FRR,因此本页部分内容描述的是旧架构。最新的建议架构请参阅「发布与稳定版」中的稳定版里程碑。
BGP / FRR Control Plane Integration Design
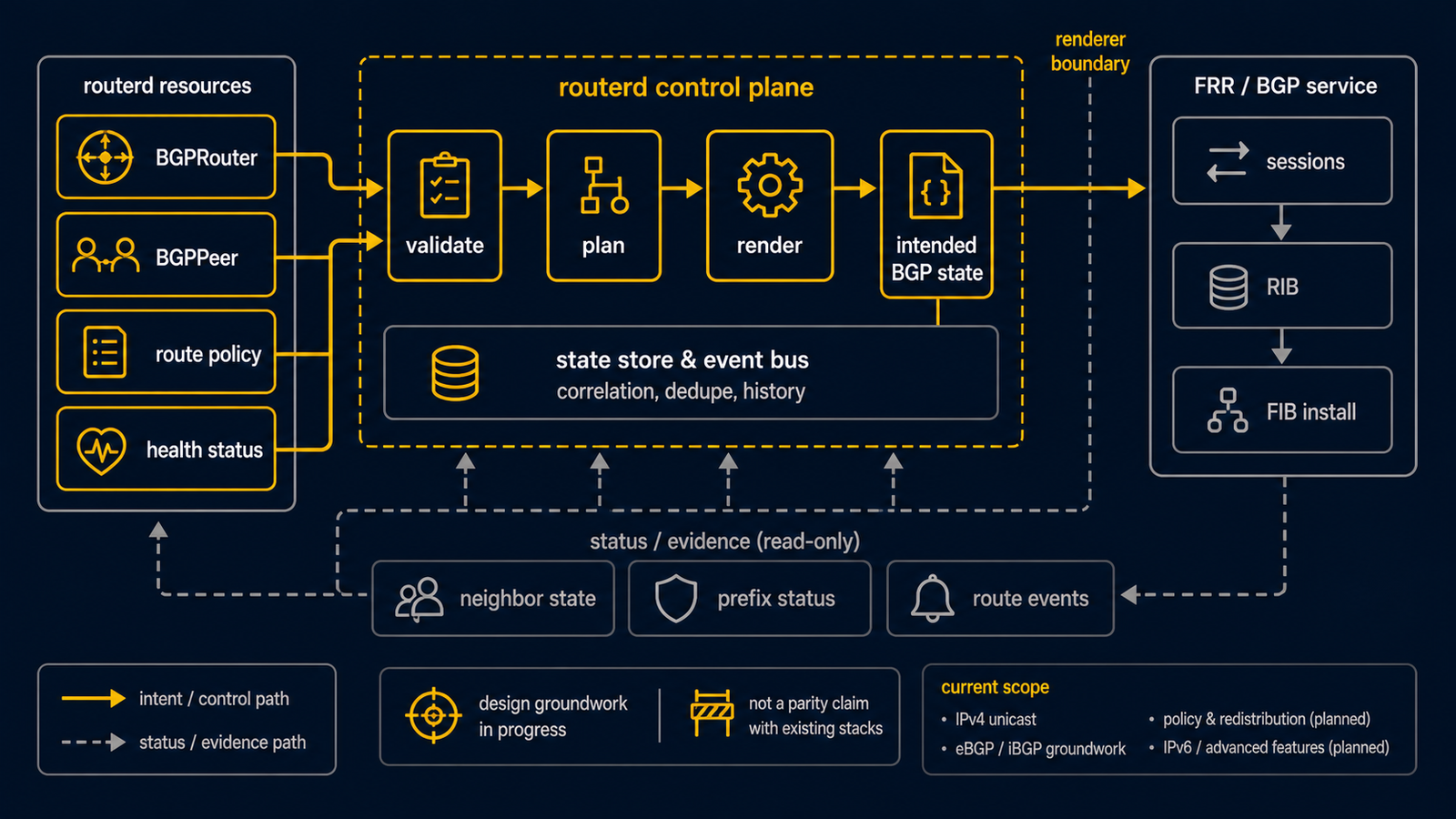
本文件说明 routerd 为了支持 BGP 及相关路由协议,与 FRR 控制平面(vtysh、frr-reload.py、守护进程 socket)交互的设计。
问题整理
在停用 TCP VTY 监听的 FRR 构建版本中(vty_serv_start() 内 port=0),routerd 原本以 tcp/2605(bgpd 的 VTY 监听端口)作为就绪判断依据,导致该判断永远为假。结果控制器会不断重启 FRR,而非对已生成(render)的配置执行 frr-reload.py,使 FRR 的 BGP 实例始终未配置完成(缺少 router bgp X 段落,也不监听 tcp/179)。
手动执行 frr-reload.py --reload /run/routerd/frr/routerd.conf 即可恢复正常。这表明已生成的配置是正确的,且 frr-reload.py 能够从无实例的状态建立 BGP 实例。
已确认的 OSS 事实(源码层级)
- FRR
lib/vty.c的vty_serv_start(addr, port, path):TCP 监听仅在port != 0时启用。Unix 的<daemon>.vtysocket 与此独立(#ifdef VTYSH)。即使是停用 TCP VTY 的发行版,Unix socket 仍存在于/run/frr/<daemon>.vty或/var/run/frr/<daemon>.vty。 - FRR
tools/frr-reload.py的is_config_available():就绪判断依据为vtysh -c "configure"成功执行,且未回报「configuration is locked」。不参考 TCP VTY 的监听状态。 frr-reload.py将「新的 BGP 实例」视为新的 context(lines_to_add)处理,因此从无实例状态首次收敛也在此脚本的处理范围内。--stdout仅重定向日志,不影响重新加载行为。
设计
就绪探测
控制器以一次 vtysh -c "show running-config" 交互来探测 FRR 控制平面:
- 退出码为 0 → 可到达 FRR 控制平面。此输出同时用作就绪信号,以及
runningConfigMatches的输入,一次交互达成两个目的。 - 退出码非 0 且消息为
failed to connect to any daemons→ 无法到达控制平面。在同一次调和(reconcile)中,于逐路径的超时到期前重试,超时后将FRRControlUnavailable呈现至 status,并由定期调和执行下次重试。 - 退出码非 0 且为其他错误 → 将 stderr 记录至 status,重试后视为无法到达控制平面。
废除基于 TCP 的判断方式。/run/frr/<daemon>.vty(及 /var/run/frr/<daemon>.vty)Unix socket 文件的存在与否,仅作为诊断信息记录至 status,绝对不作为判断依据。这是因为在守护进程初始化或重启竞争期间,文件虽存在,vtysh 交互仍可能失败。
调和流程
FRR 的服务状态是所有调和的前提条件。控制器应将「FRR 正在运行」视为每个周期都需确认并恢复的事项,而非一次性的初始化步骤。这是从 v2007 热修补中获得的经验——当时在移除错误的 TCP VTY 判断时,也一并移除了首次启动时用来启动 FRR 的路径。
1. 生成(render) /run/routerd/frr/routerd.conf 与 /etc/frr/daemons。
2. 通过平台服务管理器确认 FRR 的服务状态
(`systemctl is-active frr`):
- active/running → 不重启,继续执行。
- inactive/stopped → 启用并启动 FRR。
- failed → 重启 FRR。
- unknown → 记录日志,视同 failed 处理。
无论 /etc/frr/daemons 是否有变更,每次调和均执行此步骤。
3. 若 /etc/frr/daemons 有变更:
启用并重启 FRR(在上述状态处理之外额外执行)。
执行 waitFRRControlReady(ctx, 30s)。
4. 否则:
执行 waitFRRControlReady(ctx, 5s)。
4. 若就绪等待超时:
status = FRRControlUnavailable(若调和内的重试预算仍有余量,
则为 FRRStarting)。返回 Pending。定期调和(默认 15s)自然重试。
5. vtysh -C -f /run/routerd/frr/routerd.conf(语法验证)。
若退出码非 0:
status = FRRSyntaxInvalid(终止状态,需用户修正配置)。
6. frr-reload.py --reload --stdout /run/routerd/frr/routerd.conf。
对暂时性的 "configuration is locked" 输出,使用现有的
transient-lock 退避(500ms)重试。
其他退出码非 0 的情况:
status = FRRReloadFailed。保存 stderr。返回 Pending,
下次调和时重试。
7. 使用相同的 vtysh -c "show running-config" 确认 runningConfigMatches。
- 退出码 0 且包含生成的 `router bgp <asn>` 段落 → Healthy。
- 退出码 0 但无该段落 → 不一致 → 再次重新加载
(连续验证失败 N 次后升级为 FRRReloadIncomplete,继续重试)。
- 退出码非 0(failed to connect) → FRRControlUnavailable。
waitFRRControlReady 是可复用的辅助函数,用于守护进程重启路径(较长超时)和仅重新加载路径(较短超时)。内部会持续轮询 vtysh -c "show running-config",直到成功或超时,并在每次轮询时将 Unix socket 文件的存在与否记录为诊断信息。
Status 字段
BGPRouter / BGPPeer 的 status 对象公开以下字段:
LastControlProbeAt,LastControlProbeError:最近一次 vtysh 交互的结果。LastReloadAttemptAt,LastReloadStderr:最近一次 frr-reload.py 执行的内容(含 transient-lock 重试)。LastReloadDurationMs,TransientLockRetries:运维指标。Phaseenum 新增以下值:HealthyPendingError
- 原因与状态码:
FRRStarting(暂时性,在调和内的重试预算范围内)FRRControlUnavailable(超时已超过,由定期调和重试)FRRSyntaxInvalid(终止状态,需用户修正生成的配置)FRRReloadFailed(下次调和时重试)FRRReloadIncomplete(重新加载返回成功,但 runningConfig 中尚无生成的段落,下次调和时重试)Healthy
超时与重试预算
| 路径 | 超时 | 轮询间隔 | 定期调和 |
|---|---|---|---|
| 守护进程重启 → 就绪 | 30 s | 1 s | 继承 15 s |
| 仅重新加载 → 就绪 | 5 s | 500 ms | 继承 15 s |
| configure-locked 暂时重试 | 每次 500 ms | 最多 3 次 | — |
不设指数退避,亦无绝对失败阈值。定期调和会自然地无限重试。是否介入由操作员判断,并通过上述明确的原因码将状态呈现出来。
routerd serve 重复启动防护
scripts/build-live-iso.sh 与 live-autostart.sh 在已有 routerd serve 持有 /run/routerd/routerd.sock 的情况下,不得启动第二个实例。此防护使自动启动具有幂等性。然而,启动时的首次自动启动路径同时也是配置交接的边界。若 USB 配置还原之前启动了 routerd serve,live-autostart.sh 不应将既有进程视为成功,而必须在 apply 之后重启该服务。此重启以 reason=LiveISOStaleServeRestarted 记录日志。启动标记置于 /run/routerd 下,每次启动时重新评估此交接逻辑。若缺少重复启动防护,两个 routerd 控制器将争夺 FRR 的服务锁(rc-service / systemctl 的 flock),产生 Phase 0 记录中可见的 ERROR: frr stopped by something else 症状。若还原后未重启,早期的 serve 进程将遗漏已还原的配置,使 BGP 停留在 apply-once 的 Rendered 交接状态。
此项与 BGP 判断变更属于同一热修补,但可独立还原,且为使变更历程清晰,以独立 commit 的形式提供。
Healthy 判断(AND 条件)
BGPRouter 必须满足以下所有条件,才会进入 Healthy 状态:
- 平台服务管理器确认 FRR 的服务状态为
active/running。 - 所有声明的 FRR 守护进程(
/etc/frr/daemons中列出的)均未处于FAILED状态,且正在运行。 vtysh -c "show running-config"返回退出码 0。- 配置的地址上有
:179在监听(BGP 守护进程正在运行)。 - 输出包含生成的
router bgp <our-asn>段落。
任一条件不满足,控制器即呈现对应的原因码(详见 status 字段清单),并保持 Pending 或 Error 状态。FRR 停止期间,status 路径不得崩溃至 Healthy。v2007 的回归问题(所有 FRR 守护进程均处于 FAILED 状态,但 routerctl get status 仍回报 Healthy)正是此 AND 条件所要防范的失败模式。
验收标准
- Live ISO 启动后,恰好只有一个
routerd serve在运行,无需手动执行frr-reload.py,vtysh -c "show running-config"即出现 BGProuter bgp X,且tcp/179正在监听。 - 启动时 FRR 服务处于
FAILED状态,控制器能检测并自行恢复(无需手动执行rc-service frr start)。 - FRR 停止期间,或
:179未监听期间,routerctl get status不回报Healthy。 - 在启用 TCP VTY 的 Linux 发行版上不产生回归。
runningConfigMatches不将failed to connect视为一致。- 上述所有 status 原因码在对应的失败模式下均能产生。
测试场景
- Live ISO 首次启动:无 tcp/2605,vtysh 成功,running-config 最小化 → 执行重新加载,建立 BGP 实例,
tcp/179开始监听。 - Linux 发行版首次启动(tcp/2605 在监听):执行重新加载,runningConfig diff 与 status 均无回归。
- 从损坏状态恢复:在无 BGP 实例的 FRR 运行中的路由器上升级 routerd 二进制 → 无需手动介入即执行重新加载。
- 守护进程重启期间 vtysh 暂时
failed to connect→ 控制器在就绪预算内等待,vtysh 恢复后继续进行验证与重新加载。 - vtysh 永久失败 → 超时后显示
FRRControlUnavailable,定期调和重试。 vtysh -C -f拒绝语法 →FRRSyntaxInvalid。不执行重新加载,不产生 churn。frr-reload.py返回非 0 →FRRReloadFailed。下次调和时重试。frr-reload.py返回 0,但 running-config 中尚无生成的段落 →FRRReloadIncomplete。下次调和时重试。- 暂时发生 configure-lock → 现有的 transient-lock 重试路径成功完成。
live-autostart.sh在 serve 进程持有 socket 期间再次调用 → 不启动第二个进程,以退出码 0 退出。- Live ISO 冒烟测试(发布门控):启动新 ISO,确认 BGP 自主收敛。
- 具有持久化
routerd服务条目的 Live ISO:routerd serve可能在 USB 配置还原前启动,但live-autostart.sh会删除该服务条目,并在配置还原 +apply后重启服务,以reason=LiveISOStaleServeRestarted记录日志,因此无需手动执行frr-reload.py即可使 BGP 重新加载收敛。 - 启动时 FRR 服务处于 FAILED 状态:routerd 必须通过服务管理器启动(或重启)FRR,无需手动介入即可恢复守护进程。守护进程启动前,status 应反映 FAILED 状态。
- status 正确性:在曾达到 Healthy 状态后强制停止 FRR,下次调和必须呈现
FRRControlUnavailable或FRRServiceDown,而非Healthy。失败期间,BGPRouter status 的lastSuccessTime不得推进。
FRR Issue #8403(graceful-restart 的退出码 != 0)
FRR 8.4.x 前后的版本中,包含 bgp graceful-restart 配置时,frr-reload.py 可能返回非 0 的退出码。Live ISO 会附带较新的 FRR 版本,但需先获取 frr -v 的 Phase 0 记录,确认附带版本受影响后,才加入对应处理。不在热修补中加入投机性的版本检测代码。
架构后续对应(热修补后)
热修补合入后,将 FRR 探测与重新加载的职责切出至 pkg/frr/,提供 Prober 接口及封装所有 vtysh / frr-reload.py 调用的 DefaultProber,其方法包含 Probe、Validate、Reload、RunningConfig。如此一来,BGP 控制器将成为对 Prober 的薄层 dispatch,可进行独立的 mock 测试,并可供未来的控制器(OSPF、IS-IS 等)复用。
热修补本身为将差异最小化,暂时保留在 BGP 控制器中,并在后续发布中制定明确的迁移计划以移至 pkg/frr/。
参考资料
- FRR
lib/vty.c的vty_serv_start,vty_serv_un - FRR
tools/frr-reload.py的is_config_available, context-diff - FRR 文档:
docs.frrouting.org/en/latest/frr-reload.html - FRR Issue #8403(graceful-restart 退出码)
- VyOS
python/vyos/frr.py(参考:无预先探测的重新加载) - k8s-rt-02 的 Phase 0 记录(
/tmp/bgp-pre-reload/)